Refreshing Pelican
Two years after rebuilding this site, Pelican - the python based static site generator I use - was in need of an update. Here's a brief summary of a few meaningful changes to the build:
(and kudos to my good friend and former Google/FB engineer Sahand Saba for leading the way on all of these changes)
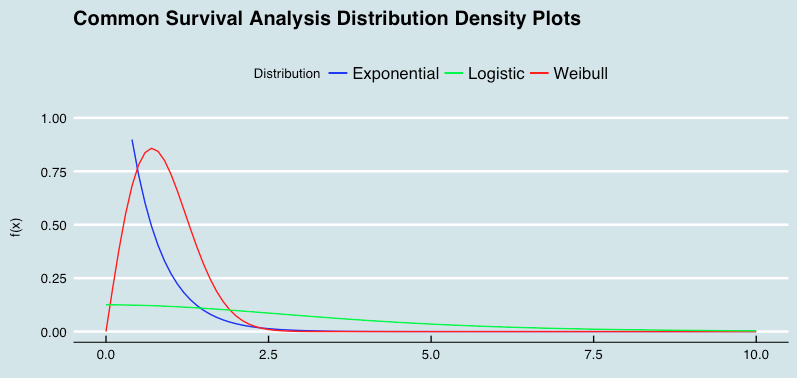
Updating Math Rendering
The original version of this site used Mathjax to render LaTeX within Markdown, which worked well for displaying equations, but there was room for speed and bandwidth improvements. Enter Katex, "the fastest math typesetting library for the web".
It has a simple installation, no dependencies, and it's own CDN. The trick is removing the need to have in-browser javascript doing the rendering.
The github project file is here: https://github.com/Khan/KaTeX
Installation is as simple as a pelican_katex.py file referenced in the pelicanconf.py file:
```` PLUGINS = ['pelican_katex'] ````
And the repo here: Sahand Saba Katex Pelican repo
Configuring HTTPS for Amazon S3
Looking up at the URL bar, you'll notice everything is now being served in https. This is thanks to a link between Amazon Cloudfront and the S3 bucket that hosts this site.
Quick links to get started are here:
Versioning Using Bitbucket
Version control is a critical but often overlooked step not only embarrassingly frequently on the enterprise level, but also for many personal projects. Rather than running iterations of the site through copied folders hosted on my personal Dropbox account, I finally got around to version control using bitbucket. Git is of course more standard, but bitbucket provides free private repositories, which is a necessity for the backend python code being used to generate the site.
Favicon
Finally, there's now a favicon of the camera logo of the old soviet era camera that constitutes my personal site logo. There's a simple generator package available on github that can generate a favicon stack to work on just about any browser or platform.